










Langchain Retriever
-
MultiQueryRetriever,利用llm为问题生成3个意思接近的问题,根据3个问题检索相关文档并全部返回。
-
MultiVectorRetriever,当同一个文档在向量库中因存储不同向量而存在多条记录时,通过id进行去重。代码实现非常简单,不知道有什么用,为什么不存储为多个向量字段而不是多个文档,可能是因为langchain的vectorstore只支持检索一个向量字段。
class MultiVectorRetriever(BaseRetriever): """Retrieve from a set of multiple embeddings for the same document.""" vectorstore: VectorStore """The underlying vectorstore to use to store small chunks and their embedding vectors""" docstore: BaseStore[str, Document] """The storage layer for the parent documents""" id_key: str = "doc_id" search_kwargs: dict = Field(default_factory=dict) """Keyword arguments to pass to the search function.""" def _get_relevant_documents( self, query: str, *, run_manager: CallbackManagerForRetrieverRun ) -> List[Document]: """Get documents relevant to a query. Args: query: String to find relevant documents for run_manager: The callbacks handler to use Returns: List of relevant documents """ sub_docs = self.vectorstore.similarity_search(query, **self.search_kwargs) # We do this to maintain the order of the ids that are returned ids = [] for d in sub_docs: if d.metadata[self.id_key] not in ids: ids.append(d.metadata[self.id_key]) docs = self.docstore.mget(ids) return [d for d in docs if d is not None] -
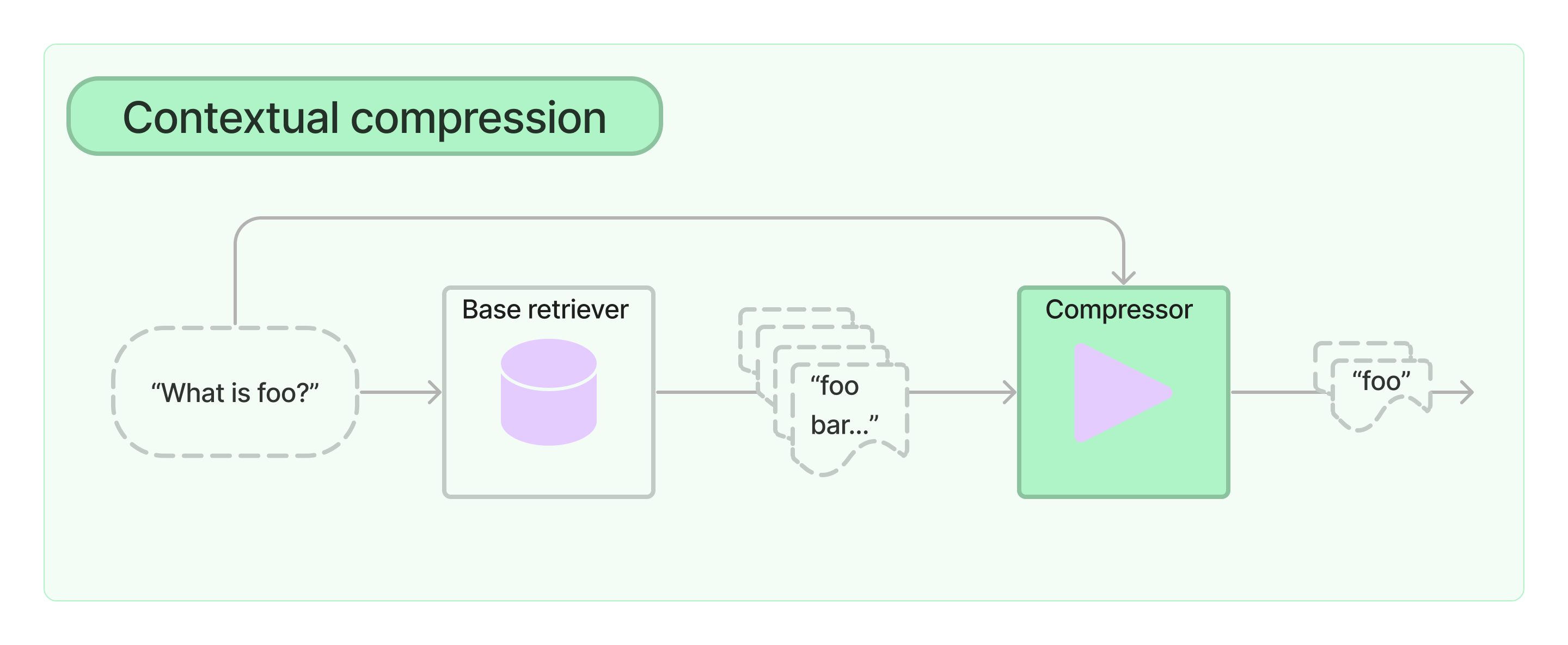
Contextual compression,检索出来的文档可能包含很多无用的上下文信息,直接扔给llm会造成干扰并且增加响应时间,使用上下文压缩的方式提高上下文和问题的相关性。这种思路的关键在于如何压缩上下文,langchain提供了几种实现。
-
DocumentCompressorPipeline,流水线,需要提供一系列
BaseDocumentTransformer或者BaseDocumentCompressor -
LLMChainExtractor,利用llm提取有效上下文信息。
-
LLMChainFilter,利用llm去除无关上下文信息。
-
CohereRerank,调用
Cohere Rerank API重排评分。 -
EmbeddingsFilter,又来一遍向量相似度度量?
-
-
Ensemble Retriever,整合一系列retrieve的结果,再进行
rrf,常见的就是全文检索+向量检索+rrf倒数排序融合,es混合搜索就是这个流程,但是rrf需要许可证。 -
Parent Document Retriever,通常切分文档时,我们既希望文档短一点,这样可以全文检索和向量检索的准确度,但是文档太短包含的信息可能太狭隘,对于关联多条文档的问题无法提供信息充分的上下文。该Retriever将文档拆分为较小的块,同时每块关联其父文档的id,小块用于提高检索准确度,大块父文档用于返回上下文,再考虑上文提到的上下文压缩,或许是一个提高检索精度的好办法。
-
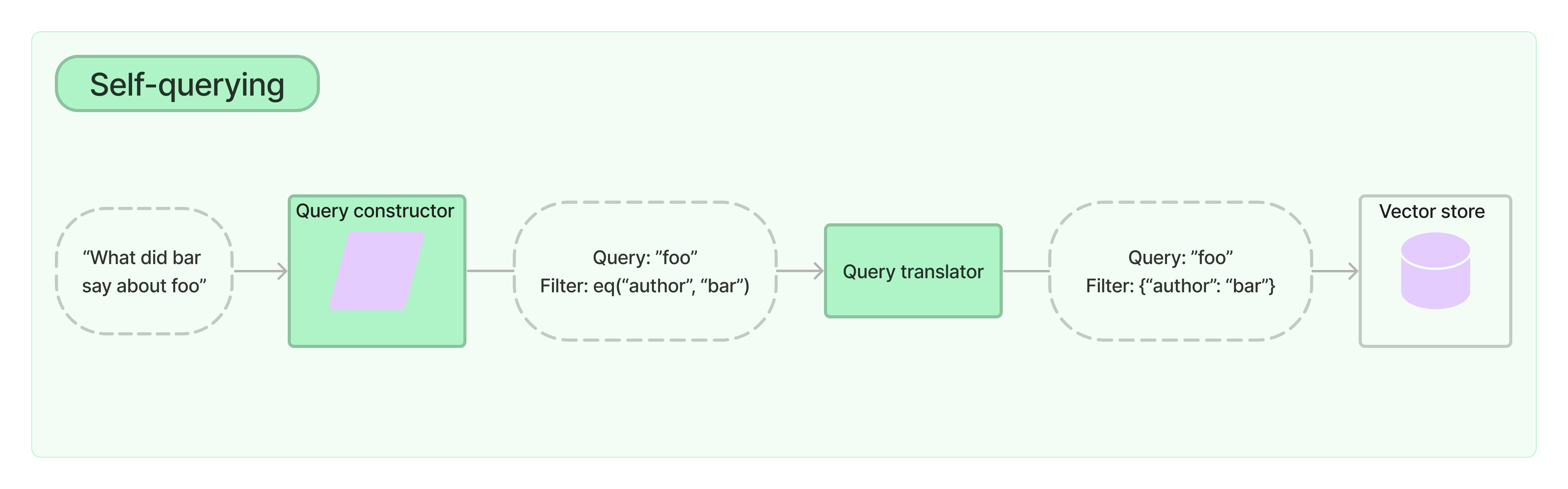
SelfQueryRetriever,由LLM将自然语言转化成查询语句。
-
TimeWeightedVectorStoreRetriever,记录上一次访问文档的时间,越久越少访问的文档评分越低。
semantic_similarity + (1.0 - decay_rate) ^ hours_passed -
WebResearchRetriever,从网络检索内容以提供上下文。
在
langchain.retrievers包下还有很多检索增强的类。
Elasticsearch向量检索
dense_vector类型
不支持聚合和排序,不能在嵌套字段中,否则无法被索引。
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 1023,
"index": true,
"similarity": "dot_product"
}
}
}
}
支持的属性
-
element_type
- float,默认,4字节浮点数。
- byte,1字节整数,-218~127。
-
dims,必填字段,向量维数,不能超过2048。
-
index,默认为fasle,设置为true支持kNN搜索。
-
similarity,相似度度量算法,如果index为true,该字段必须设置。
- l2_norm,欧式距离
- dot_product,点积
- cosine,余弦相似度
建议归一化向量,选择dot_product方式,提高检索效率。
-
index_options,可选字段
- type,必填字段,kNN算法,目前只支持hnsw。
- m,必填字段,hnsw中每个节点的邻节点数,默认值16。
- es_construction,必填字段,汇聚每个新节点的邻接点时,跟踪的节点数量,默认是100。
kNN检索
通过相似性度量搜索k个最邻近向量,es比较新的版本已经自带模型,不需要在应用程序中编码文本字段和查询语句,elastic云支持自己上传模型,但是似乎这个功能不免费?
近似kNN
消耗资源少,响应快,牺牲精确度
注意事项
-
dot_product还是cosine建议归一化向量,选择dot_product方式,提高检索效率;cosine无需归一化,可直接计算。
-
足够的内存
Elasticsearch使用HNSW算法进行近似KNN搜索。HNSW是一种基于图的算法,向量保存在内存中才能有效工作。所以需要保证数据节点有足够的内存保存向量数据和索引结构。要查看向量数据的大小,es提供了API分析索引磁盘使用情况。从经验来说(使用默认的HNSW配置),使用
float类型,占用字节近似num_vectors * 4 *(num_dimensions + 12)。当使用byte类型,所需的空间近似num_vector *(num_dimensions + 12)。这里所指的空间是文件系统缓存,而不是Java堆。 -
预热文件系统缓存
当es启动时,文件系统缓存为空,开始的检索可能会比较慢,可以预加载索引数据来建立缓存,但是如果加载太多数据到文件系统缓存,可能减慢检索速度。
近似kNN检索需要的数据文件后缀
- vec,向量值
- vex,HNSW图
- vem,元数据
-
降低向量维度
向量维数越大计算越耗资源,有的模型可以选择不同的编码维度,也可以使用降维方法减少维度,在准确度和检索速度之间做取舍。
-
不要返回向量字段
加载向量数据返回耗费时间,可以使用
_source从返回结果中排除这个字段,关于如何排除字段以及性能影响,可以查看ElasticSearch中_source、store_fields、doc_values性能比较,es官方文档。 -
还有几个点涉及到es的底层数据结构,需要一定的调优能力,可以查看官方文档
kNN选项
-
field,必填,向量字段名 -
filter,可选,query dsl的filter,向量检索之后再由filter过滤。 -
k,必填,返回的邻近向量数,必须小于num-candidates。 -
num-candidates,相当于每个分片上的k,es从每个分片上检索num_candidates个向量结果,再根据评分汇总返回k个最终结果。增大该值可以提高检索结果的准确度。 -
query_vector,可选,要检索的向量,维度必须和创建mapping时一致。 -
query_vector_builder,可选,指定模型的相关信息,将编码文本为向量的任务交给es。query_vector和query_vector_builder,必须填且只能填一个。 -
similarity,可选,float类型,判定检索命中的一个阈值,与所选的距离度量方式有关,不是文档分数_score,通过该值对文档进行评分,并应用boost(如果有)。以下是个人理解,不一定准确(英文没看懂)
如果是
l2_norm,距离需要小于等于similarity如果是
cosine或者dot_product,相似度需要大于等于similarity。 -
boost,计算评分时的系数。
精确kNN
查询所有文档计算相似度以保证结果的准确度,可以先使用query过滤一部分文档,再进行精确kNN提高检索速度。
如果确定字段不需要进行近似kNN,可以将字段的index属性设置为false,可以提升索引速度。
精确kNN使用script_score查询
{
"query": {
"script_score": {
"query" : {
"bool" : {
"filter" : {
"range" : {
"price" : {
"gte": 1000
}
}
}
}
},
"script": {
"source": "cosineSimilarity(params.queryVector, 'product-vector') + 1.0",
"params": {
"queryVector": [-0.5, 90.0, -10, 14.8, -156.0]
}
}
}
}
}
语义检索
es所谓的语义检索即是自带的模型以及向量检索,es提供了一些NLP模型,包括密集向量和稀疏向量的,如果进行中文搜索,需要自己上传配置模型。提高语义检索的通常步骤是选择一个效果较好的通用模型,积累语料,对模型进行训练,优化效果。但训练的成本并不低,为了提供一个通用简便的使用,es提供了一种稀疏编码器ELSER,开箱即用,尽量减少微调,目前仅适用于英语。
简单来说,语义检索就是将模型编码的工作也交给了es,不需要我们提前编码好再发送给es进行距离计算。包括部署模型、创建向量字段、生成嵌入向量、检索数据四个步骤。这个功能不免费,具体可以查看官方文档。
Langchain整合Elasticsearch
self._embeddings = HuggingFaceBgeEmbeddings(model_name=Configuration.EMBEDDING_MODEL,
model_kwargs={'device': Configuration.DEVICE},
encode_kwargs={'normalize_embeddings': True})
self._es_client = Elasticsearch(hosts=f'http://{Configuration.ES_HOST}:{Configuration.ES_PORT}',
basic_auth=(Configuration.ES_USER, Configuration.ES_PASSWORD))
self._es_vector_store = ElasticsearchStore(index_name=Configuration.INDEX_NAME, embedding=self._embeddings,
es_connection=self._es_client,
distance_strategy=DistanceStrategy.DOT_PRODUCT,
strategy=ApproxRetrievalStrategy(hybrid=True, rrf=True)) # 混合检索,rrf重排
如果没有提前建立索引,es会自动创建索引,增加向量字段,其他的字段均由es自动推断类型,如果需要使用全文检索,需要创建索引时指定分词器,同时检索时只能检索一个向量字段和一个文本字段,部分参数无法灵活定义,并不是太好用。建议自己手搓添加文档和搜索文档的过程。
Q.E.D.

