










Mybatis运行流程源码分析
SqlSessionFactory构建
以XML文件配置为例
这一步就是创建XMLParser解析主配置文件以及所有mapper文件的过程,所有的相关信息都被保存在Configuration对象中,最终返回一个DefaultSqlSessionFactory对象。
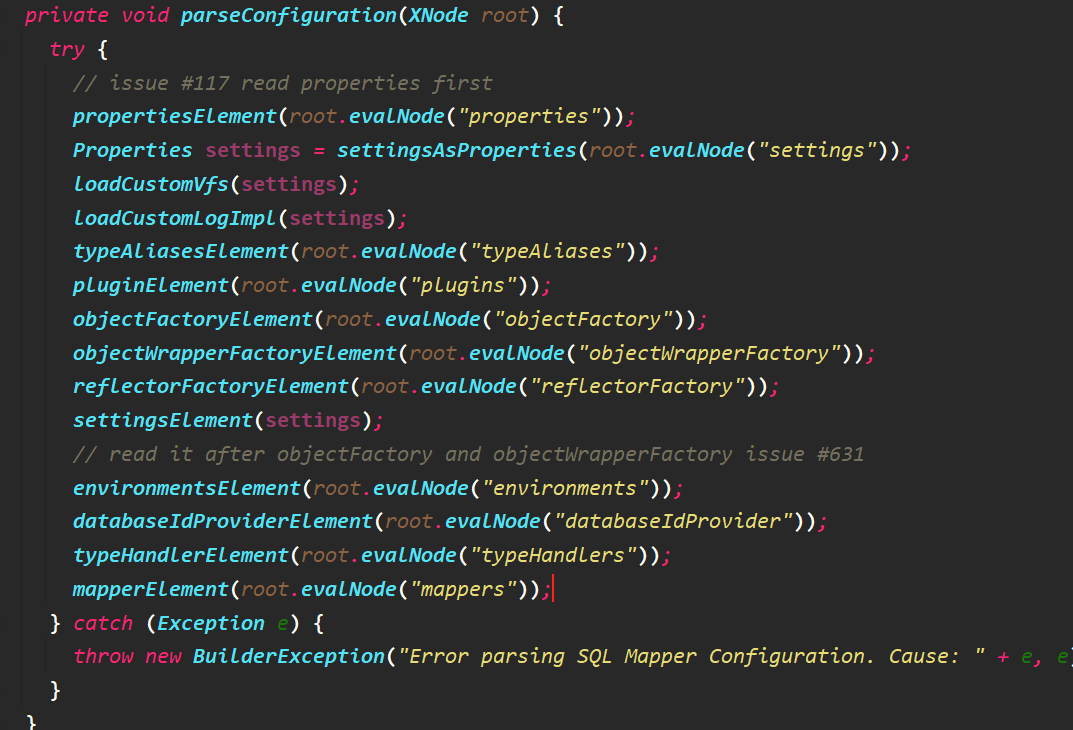
依次解析每一个节点及其子节点
对于每一个mapper文件,都有对应的XMLMapperParser解析
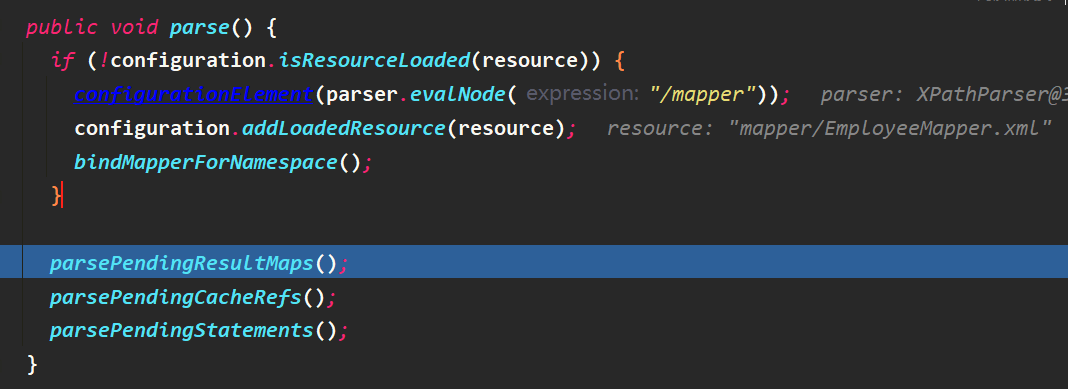
在XMLStatementBuiler对象中,解析了每个增删改查标签的所有属性,构建了MappedStatement对象。
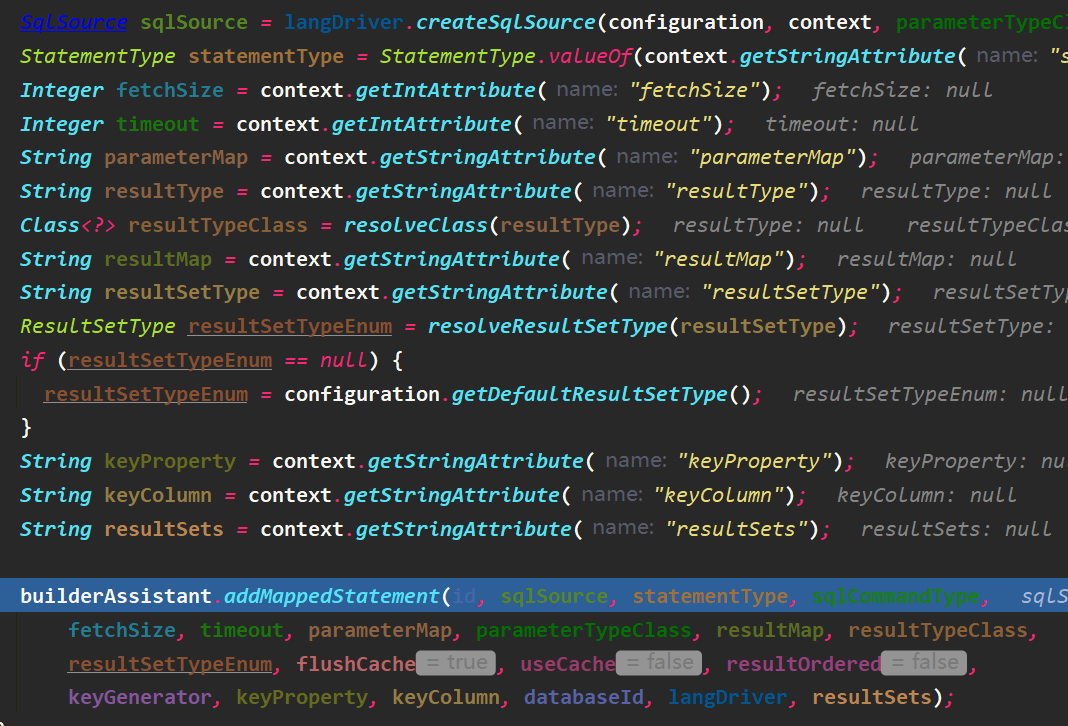
我们在mapper中写的每个CRUD标签,都被解析成了MappedStatement对象,该对象的属性较多,可自行源码查看。
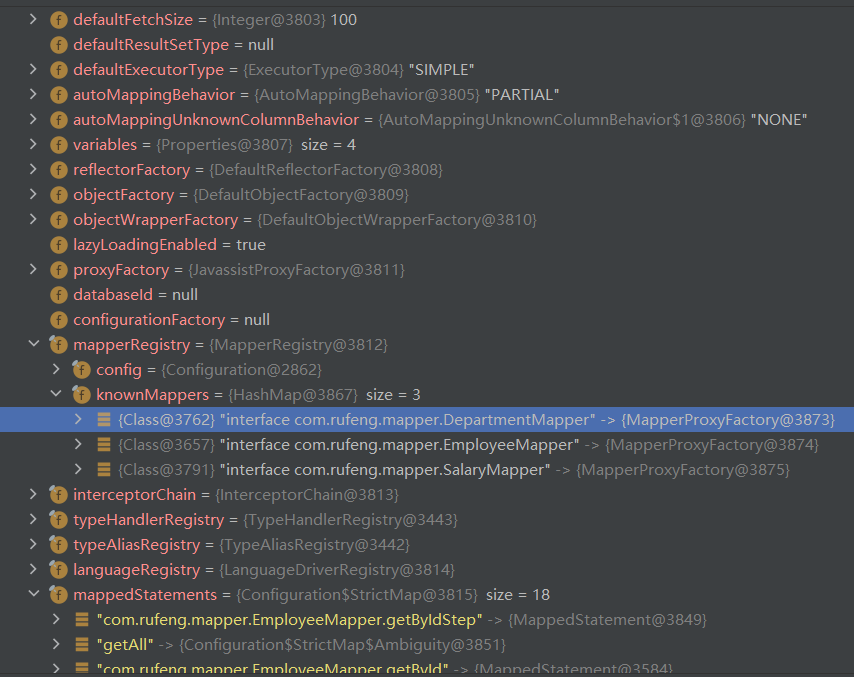
最终Configration对象包含了所有XML配置中的信息,我们编写的Mapper接口最终是由MapperProxyFactory生产为JDK动态代理的MapperProxy对象。
整个XML文件解析不是我们分析的重点,了解大概的流程即可。
openSession获取SqlSession对象
这一步只需要分析DefaultSqlSessionFactory对象了,openSession方法的主要逻辑如下
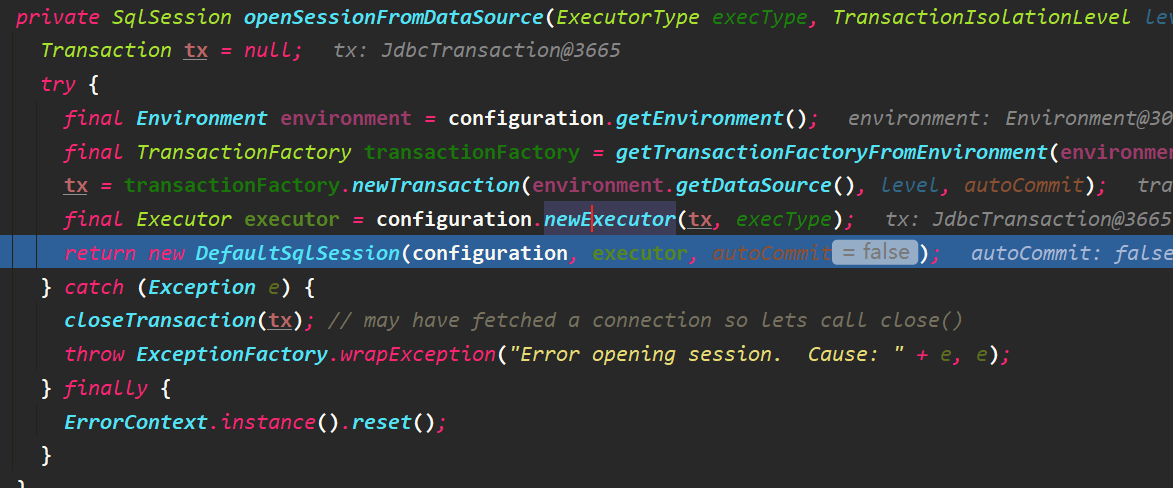
executeType有三种,SIMPLE、REUSE、BATCH,Excutor对象是非常重要的一个类,顾名思义为SQL执行器。
进入newExecutor方法
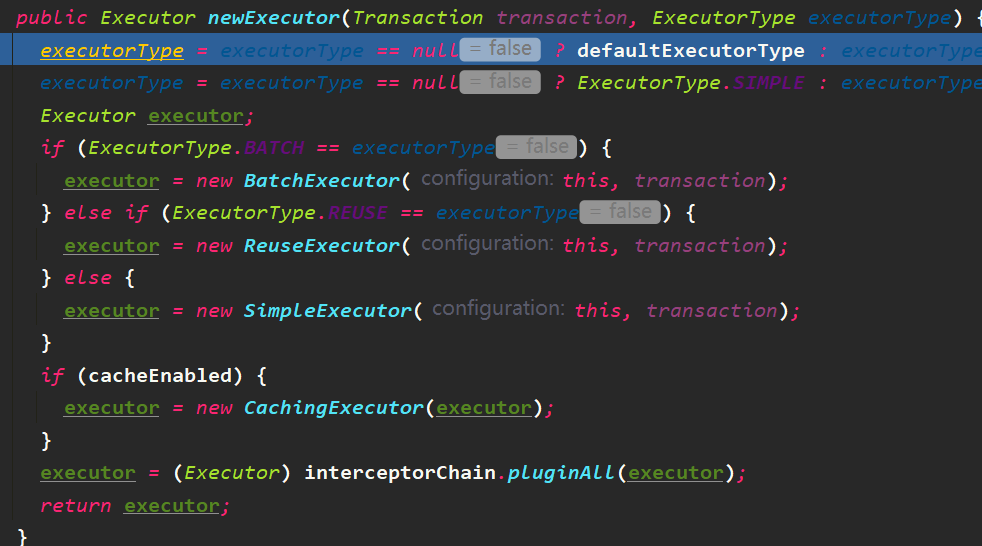
- 根据配置的executorType创建不同的Executor对象,如果启用了二级缓存,会包装成CachingExecutor。
- 安装了插件,第一次出现。
最终返回了一个SqlSessiond对象,进入SqlSession类中查看增删改查方法,发现其最终调用了excutor成员的方法。
getMapper获取MapperProxy
- SqlSession的getMapper方法调用其成员Configuration的getMapper
- Configuration的getMapper方法调用MapperRegistry的方法,MapperRegistry中的knownMappers以map方式存储了所有mapper接口,key为对应Mapper接口的Class对象,值为前面提到的MapperProxyFactory对象。
- 通过JDK动态代理生成一个MapperProxy对象,代理对应接口的方法。
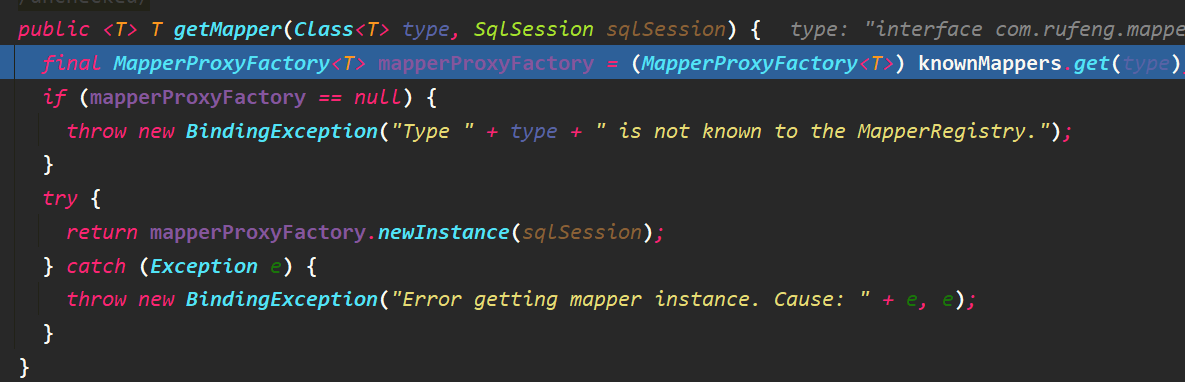
MapperProxyFactory类的源码非常简单,感兴趣可自行查看。
Mapper方法执行流程
动态代理invoke方法
调用Mapper的方法后,直接进入JDK动态代理的invoke方法
try {
if (Object.class.equals(method.getDeclaringClass())) {
/* Object类的方法,如equals、toString等 */
return method.invoke(this, args);
} else {
/* 找到匹配的MapperMethod,调用其invoke方法 */
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
执行mapperMethod
判断该方法的sql语句类型及返回数据类型,然后执行SqlSession封装的对应方法。其中,convertArgsToSqlCommandParam解析方法参数
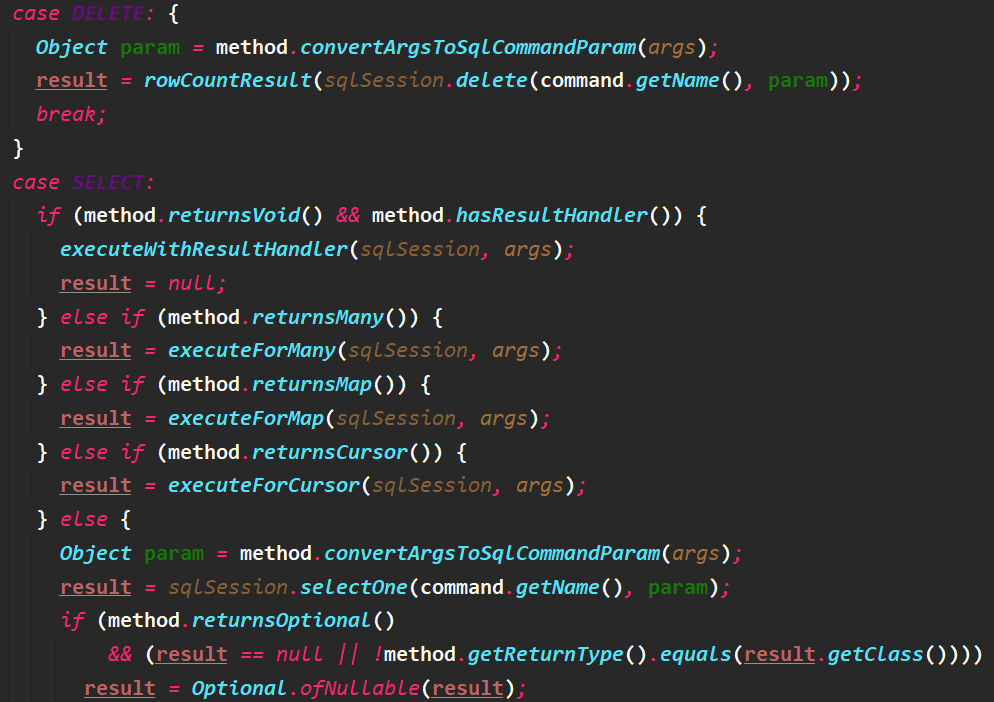
参数解析
final int paramCount = names.size();
if (args == null || paramCount == 0) {
return null;
} else if (!hasParamAnnotation && paramCount == 1) {
Object value = args[names.firstKey()];
return wrapToMapIfCollection(value, useActualParamName ? names.get(0) : null);
} else {
final Map<String, Object> param = new ParamMap<>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
param.put(entry.getValue(), args[entry.getKey()]);
// add generic param names (param1, param2, ...)
final String genericParamName = GENERIC_NAME_PREFIX + (i + 1);
// ensure not to overwrite parameter named with @Param
if (!names.containsValue(genericParamName)) {
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
参数有多个或者包含@Param注解后会被封装成map,之后再调用wrapIfCollection方法,否则直接调用
public static Object wrapToMapIfCollection(Object object, String actualParamName) {
if (object instanceof Collection) {
ParamMap<Object> map = new ParamMap<>();
map.put("collection", object);
if (object instanceof List) {
map.put("list", object);
}
Optional.ofNullable(actualParamName).ifPresent(name -> map.put(name, object));
return map;
} else if (object != null && object.getClass().isArray()) {
ParamMap<Object> map = new ParamMap<>();
map.put("array", object);
Optional.ofNullable(actualParamName).ifPresent(name -> map.put(name, object));
return map;
}
return object;
}
可以看到,collection,array都是直接写死放入map的
执行sqlSession封装的CRUD方法
通常我们使用都是获取Mapper代理对象后调用其方法,Mybatis会解析调用的方法的全限定、和参数信息,再调用sqlSession的方法。
我们也可以直接调用sqlSession的方法,本质上没有区别,只是前者方式下程序员的工作量更小了。
根据方法的全限定名获取MappedStatement对象,再由excutor执行
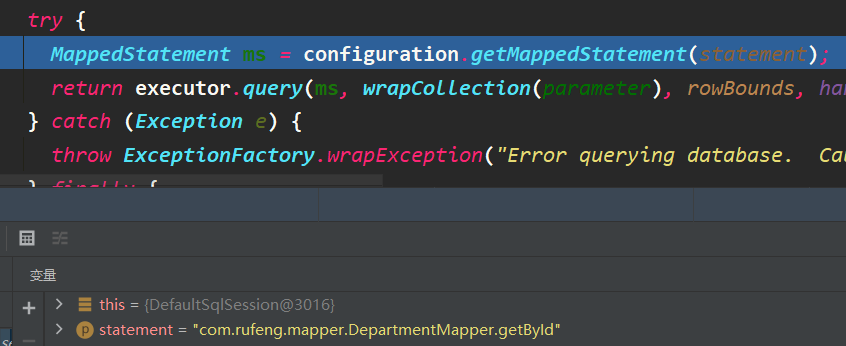
依据sql语句、参数等创建缓存的key
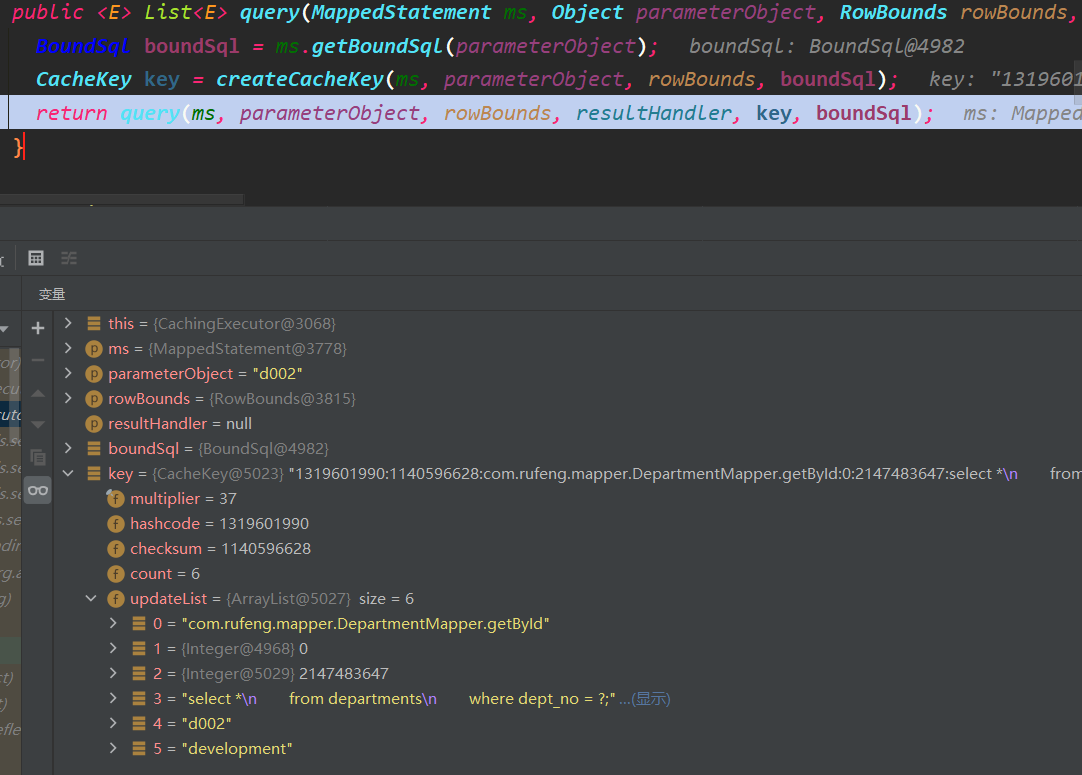
- ms:MappedStatement对象,此时s所有#使用?占位符替代
- parameterObject:参数信息
- rowBounds:逻辑分页
- resultHandler:实现ResultHandler接口,返回结果的钩子
- key: 缓存key中包含了mapper方法信息、sql语句、参数、逻辑分页、数据库标识,开发环境等,如下图所示
- boundSql:sql语句相关信息
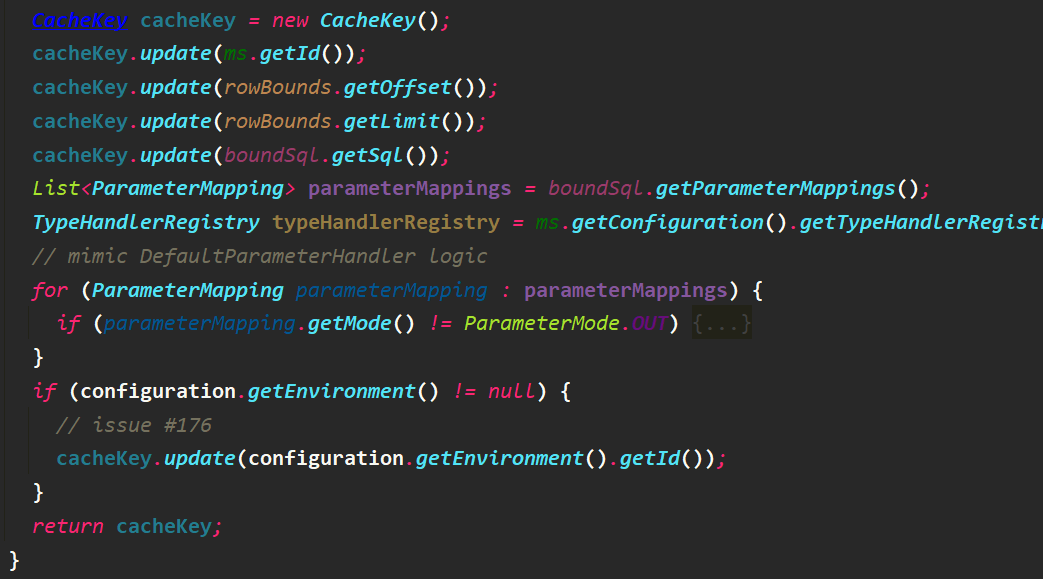
首先查询二级缓存
public <E> List<E> query(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
/* statement的二级缓存,在对应的mapper中配置了cache后才有效 */
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
/* 从该mapper对应的cache中获取 */
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
/* 并未真正进如缓存,事务提交之后才进入缓存 */
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
/* 二级缓存无效,走Executor的方法 */
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
二级缓存由TransactionalCacheManager管理,put时,会调用TransactionalCache的put方法将待缓存对象放到entriesToAddOnCommit中,是一个Map对象,当该会话关闭或事务提交时,会调用TransactionalCache的flushPendingEntries真正缓存到delegate对象中,这才是真正的缓存区。
具体可查看Mybatis缓存
一级缓存与数据库查询
二级缓存未命中,进入以下代码
/* 清除缓存 */
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
/* 尝试一级缓存 */
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
/* 走数据库 */
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
默认一级缓存的实现是PerpetualCache,简单的哈希表
从数据库查询
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
/* 标志正在执行sql查询,占位符 */
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
/* 查数据库 */
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
/* 结果放入缓存 */
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
可以看到,每个sqlSession会有一个自己的localCache,缓存使用哈希表实现,这就解释了为什么一级缓存只在会话中有效。
原生jdbc查询
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
/* jdbc Statement */
Statement stmt = null;
try {
/* 全局config */
Configuration configuration = ms.getConfiguration();
/* StatementHandler接口,分阶段对statement处理 */
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
/* 原生jdbc statement预编译 */
stmt = prepareStatement(handler, ms.getStatementLog());
/* 送去执行 */
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
newStatementHandler方法
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
- 在 RoutingStatementHandler方法中,判断statement的type类型,XML配置中的statementType,根据配置可以返回
- SimpleStatementHandler,对应XML中的statement
- PreparedStatementHandler,对应XML中PREPARED,默认
- CallableStatementHandler,对应CALLABLE,存储过程
- 在这里,再次出现了pluginChain,安装插件,第二次出现
上述StatementHandler三者全部继承自BaseStatementHandler,在BaseStatementHandler的构造方法中,初始化了两个成员

在这两个成员的构造函数中,有以下代码
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
至此,pluginAll出现四次
prepareStatement方法
private Statement prepareStatement(StatementHandler handler, Log statementLog)
throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
- 获取连接,根据statement的参数配置,可能获取不同连接,例如,不同数据库
- 准备阶段,设置fetchSize、timeOut等
- 填充参数,依赖Parameterhandler完成在这个阶段会使用到typeHandler、JdbcType完成参数类型映射
该部分就是对原生jdbc操作令人难受的部分的操作。
至此,等待数据库返回结果,整个查询流程结束了。
statement到此准备完毕了,可以送去执行了。
送到数据库执行
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleResultSets(ps);
}
执行的返回结果由ResultSetHandler处理后返回。
总结
待续。。。
关于四次pluginAll方法,插件原理,请看Mybatis插件原理
Q.E.D.

