










Hive
以下是对尚硅谷Hive3.1教程的个人总结
Hive基本概念
基于Hadoop的数据仓库工具,本质上是将结构化的数据文件映射为一张表,提供类似SQL的查询功能。
- 数据存储在HDFS。
- 查询分析数据底层的默认实现是MapReduce。
- 执行程序运行在Yarn上。
Hive优缺点
优点
- 避免写MapReduce,类SQL查询,学习使用成本低。
- 大数据量计算优势。
缺点
- 执行延迟高,数据量达到一定量级才有优势。
- 对DML语言支持较差。
- 数据挖掘、迭代式算法无法表达。
Hive架构
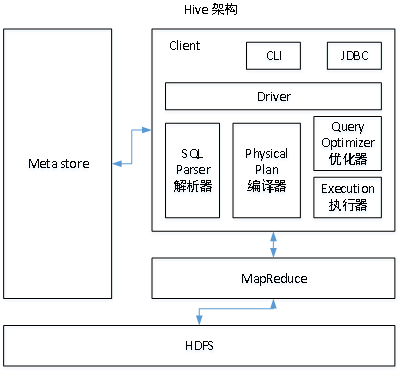
和传统关系型数据库的架构很像。
-
元数据中存储了HDFS文件映射的表的信息,包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。传统数据库中这些信息存储在自身元数据库中,Hive默认存储在Derby数据库。
-
传统数据库数据查询计算由存储引擎与Server层完成,Hive默认由Hadoop的MapReduce完成。
-
传统数据库一般有自己的数据文件格式,将数据保存在块设备或者本地文件系统;Hive是结构化的数据,即使直接从HDFS下载也能方便快速解析。
-
Hive没有传统数据库索引的概念,对每一个数据文件都要全表扫描,Hive使用分区拆分文件到不同文件夹,减少扫描数据量。
Hive管理表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
-
内部表
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
-
外部表
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
内外部表转换
alter table tablename set tblproperties('EXTERNAL'='TRUE');
分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
分区表加载数据
由于表的元数据信息是由Hive维护在MetaStore中的,所以数据的插入如果不经过Hive,则元数据中不会有修改,可能产生一些问题。
对于分区表来说,如果直接使用dfs命令上传文件到HDFS,需要进行分区修复或添加。
创建分区目录,上传到指定分区,再使用以下命令修复
msck repair table tablename
-- 或
alter table tablename add partition(field1=value1,field2=value2)
排序
-
ORDER BY
全局排序,一个Reducer,比较耗时。
-
SORT BY
每个Reducer内部排序,当只有一个Reducer时,等价于ORDER BY。
-
DISTRIBUTE BY
类似MR进行分区,结合SORT BY使用,必须写在SORT BY之前。
-
CLUSTER BY
当distribute by和sorts by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序。
统计分析函数
窗口函数
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化;
CURRENT ROW:当前行;
n PRECEDING:往前n行数据;
n FOLLOWING:往后n行数据;
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点;
LAG(col,n):往前第n行数据;
LEAD(col,n):往后第n行数据;
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
Rank
RANK() 排序相同时会重复,总数不会变。
DENSE_RANK() 排序相同时会重复,总数会减少。
ROW_NUMBER() 会根据顺序计算。
文件存储格式
-
TEXTFILE
默认文件存储方式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大,数据不支持分片,数据加载导入方式可以通过LOAD和INSERT两种方式加载数据。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压)
,但使用gzip方式,hive不会对数据进行切分,从而无法对数据进行并行操作,但压缩后的文件不支持split。在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。 -
SEQUENCEFILE
Hadoop
API提供的一种二进制文件,以key-value的形式序列化到文件中,存储方式为行式存储,sequencefile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,RECORD是默认选项,通常BLOCK会带来较RECORD更好的压缩性能,自身支持切片。数据加载导入方式可以通过INSERT方式加载数据,现阶段基本上不用。
-
ORC
ORCFile是RCFile的优化版本,hive特有的数据存储格式,存储方式为行列存储,具体操作是将数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引,自身支持切片,数据加载导入方式可以通过INSERT方式加载数据。
自身支持两种压缩ZLIB和SNAPPY,其中ZLIB压缩率比较高,常用于数据仓库的ODS层,SNAPPY压缩和解压的速度比较快,常用于数据仓库的DW层
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
-
PARQUET
Parquet 是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
是一个面向列的二进制文件格式,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。Parquet一般使用Snappy、Gzip压缩,默认是Snappy。
Q.E.D.

